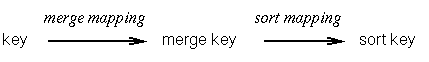
Congratulations! You have made a good decision, indeed.
For a first impression, how a style file can be written from scratch reference the tutorial that comes with this distribution. It is written as a guided step-by-step practicing exercise and you can learn the basic concepts quite easily.
Afterwards, the best starting point is to make a copy of the template
file that contains all the necessary commands that are needed to make
a makeindex-like index. You can find it in the subdirectory
markup/tex of the module library. Starting from this template
you can remove or add commands as necessary.
Additionally, consult the library of predefined index style modules that comes with this distribution. Solutions for most of the typical problems can be found there, such as a module for doing case-insensitive sorting rules, or a typical TeX-like markup. Most of the time is is enough to include some of these modules and add a few additional commands.
Maybe some of the examples coming with the test-suite are good examples of how unusual index style files can be written.
Thus, there are many ways to learn writing an index style file. But it is very easy and after some experience you can process indexes your friends will be jealous of.
Copy the file tex/makeidx.xdy from the library to your
local directory. It is documented in in a way that should make it easy
to fill in new commands or remove or modify others.
makeindex with
The treatment of the actual key (usually denoted with @, the
at-sign) has changed with makeindex with the actual key. The
makeindex-3 system and
\index{\bf{VIP}}
which can be transformed with a rule like
(merge-rule "\bf{\(.*\)}" "\1" :again :bregexp)
which removes the macro definition for merging and sorting keywords, but keeping the original definition for markup purposes. Therefore we don't need any actual keys for all keywords written in boldface.
The makeindex behaviour, that the two keywords
\index{VIP}
\index{VIP@\bf{VIP}}
are seen as two distinct index entries, can be simulated using the following definition:
(merge-rule "\bf{\(.*\)}" "\1~e" :again :bregexp)
This rule tells ~e, which is the last character in the
alphabet (ISO-Latin in our case). This makes
Keyword: Merged and sorted as: Appears in the index as:
VIP VIP VIP
\bf{VIP} VIP~e \bf{VIP}
With this new style of writing keywords and defining their markup, the
need to explicitly specifying the print key (aka. actual key) has
convinced us to remove the makeindex way of defining keywords.
What makes makeindex hardly usable in non-English speaking
countries is its lack of support of language specific alphabets and
sort orderings. For example, many roman languages such as Italian,
French, Portuguese or Spanish contain accented letters such as
À, Á, ñ. Other languages from northern Europe
have letters like Ä, Ø, æ or ß which often
can't even be processed by many index processors let alone sorting
them correctly into an index.
Two problems must be solved when processing indexes with a new languages:
The
The keyword mappings are as follows: The merge key is generated
from the main key with the so called merge mapping. The
merge mapping can be specified with the command merge-rule. The
sort key is derived from the merge key using the sort
mapping specified with the sort-rule command. The following
scheme shows this mapping process:
The index style commands accomplishing this task are
sort-rule and merge-rule. One example of such a rule would
be
(sort-rule "�" "ae")
defining that a word containing the umlaut-a will be sorted as if it
contained the letters ae instead. This is one form of how the
umlaut-a (�) is sorted into german indexes. With an appropriate set of
rules on can express the complete rules of a specific language.
An example of how an appropriate mapping for some of the Roman languages could look like is:
(sort-rule "�" "a")
(sort-rule "�" "a")
(sort-rule "�" "a")
(sort-rule "�" "e")
(sort-rule "�" "e")
(sort-rule "�" "c")
This makes the accented letters be sorted as their unaccented counterparts, yielding the desired sort ordering.
Sometimes it is necessary to specify keyword mappings that tell the
system to put something behind something else. For instance, we'd
like to map the character � behind the letter o. No problem
if you use the special characters ~b and ~e which
are called the beginning and ending characters. The first
letter lexicographically precedes all other letters whereas the latter
one comes after all others. Our mapping problem can now be specified
as follows.
(sort-rule "�" "o~e")
Now the � is directly positioned after the o but before p.
See the manual for a detailed description of this feature. Also be informed that the keyword mappings can be specified with regular expressions. Rules of the form
(merge-rule "[-$()]" "")
are possible. This on removes all letters of the defined letter class. Regular expression substitutions are possible as well. Refer to the manual for an exact description.
The default sort ordering sorts letters according to their ordinal number in the ISO Latin alphabet. As a consequence the lowercase letters appear before the uppercase letters. To sort them case-insensitively use the command
(require "lang/latin/caseisrt.xdy")
This module defines the appropriate sort rules for the letters `A-Z' for latin-based alphabets. If your language has more letters simply add the missing ones into your style file. Have a look at the module to see how to the sort rules are defined.
Letter groups for latin based alphabets can be defined with the command
(require "lang/latin/letgroup.xdy")
If your language needs additional letter groups you can insert them into the previously defined letter group with inserting definitions of the following form:
(define-letter-group "ly" :after "l" :before "m")
(define-letter-group "ny" :after "n" :before "o")
This adds two more letter groups to the latin alphabet. Group ly is inserted between l and m, and ny is inserted between n and o. This is how two additional letters of the Hungarian alphabet can be inserted.
Assume you have index entries containing arbitrary formatting information. For example you write your index entries in TeX in the following form:
\index{\bf{In boldface please}}
To avoid specifying for each index entry the print key separately as can be done with the following command
\index{In boldface please@\bf{In boldface please}}
you can instead define a rule doing this task for you:
(merge-rule "\\bf *{(.*)}" "\1" :eregexp :again)
This extended regular expression matches all strings that are surrounded by this formatting command and in the merge phase the formatting command is simply stripped off. Thus, you don't need to write an explicit print key anymore.
If for some reason the same word appears more than once in the index, each time having another markup tag as in the following example
index
{\tt index}
you must be warned that a rule like
(merge-rule "{\\tt *(.*)}" "\1" :eregexp :again)
is probably not correct. In this case the above strings are both
mapped into the string index thus joining their location
references into one index entry. This happens because the result of
the merge mapping is used as the equality citerium which views both
keywords as equal. To avoid this you should specify instead
(merge-rule "{\\tt *(.*)}" "\1~e" :eregexp :again)
With the additional meta character ~e the substitution of the
second key word is placed after the first one making them
different index entries. If the second keyword should appear first,
use ~b instead.
Especially for hierarchical indexes sometimes the result is not as expected due to special characters appearing in the keyword. In the following example the word `card' should appear before `-eyed' since the hyphen should not count as an ordinary character by means of sorting.
green
-eyed 12
card 15
This is especially problematic if the list of words on the second level is very long. To make the hyphen be simply ignored during the sorting process you should specify the following command in the index style:
(sort-rule "-" "")
This makes `-eyed' be sorted as `eyed' thus making it appear after `card' as desired.
According to the Chicago Manual of Style there exist two
different schemes of sorting word lists. In word ordering
a blank precedes any letter in the alphabet, whereas in letter
ordering it does not count at all. The following example borrowed
from the makeindex man-page illustrates the difference:
Word Order: Letter Order:
sea lion seal
seal sea lion
By default,
(require "ord/letorder.xdy")
It actually defines the following command:
(sort-rule " " "")
This simply removes all blanks from the keyword resulting in the desired behaviour.
The ability to deal with user-definable location structures is one of
the most important new features of
A location class is defined by a sequence of alphabets. An alphabet
can be the set of arabic numbers (0, 1, 2, ...) or the roman numerals
(i, ii, iii, ...). These are built-in alphabets in
(define-alphabet "weekdays"
("mon" "tue" "wed" "thu" "fri" "sat" "sun"))
Based on alphabets one can now compose a location class as follows:
(define-location-class "weekday-hours"
("weekday" :sep ":" "arabic-numbers"))
This class description indicates that all location refernces matching
this template are viewed as correct instances of this class. Here
:sep makes the dot serving as a separation string separation
the alphabets from each other. Example instances of this class are:
mon:23, thu:45, sun:17
For more detailed information consult the description of the command
define-location-class in the reference manual.
By default,
12, 13, 14, 15, 16
would be shorter represented as
12-16
If you don't want to have ranges, simply define your location class in the form
(define-location-class ... :min-range-length none)
The argument :min-range-length none avoids forming of ranges.
Arbitrary numbers instead of none define the minimum length of a
sequence of location references that are needed to form a range.
A common way of tagging ranges is as follows: a range of length 1 is printed with the starting page number and the suffix `f.', those of length 2 with suffix `ff.', and all others in the form `X--Y'.
Assume we want to do this for the location class pagenums we can specify the markup as follows:
(markup-range :class "pagenums" :close "f." :length 1 :ignore-end)
(markup-range :class "pagenums" :close "ff." :length 2 :ignore-end)
(markup-range :class "pagenums" :sep "--")
The first command indicates that a range (X,Y) of length 1 should
be printed in the form Xf., a range of length 2 as Xff. and
all others in the form X--Y. The switch :ignore-end causes
the end of range location reference Y to be suppressed in the
resulting output.
Sometimes it is necessary to hide some of the parts of the index. If you have a text formatter that allows comments or macros that possibly expand to nothing, just define appropriate markup that makes things invisible to the formatter. For example, with TeX you can define a macro like this
\def\ignore#1{}
If you additionally define markup like this
(markup-index :open "\ignore{" :close "}")
you can throw away the complete index if you like, which would be a real pity!
Cross references are references pointing to an item in the index itself. Typical examples are:
foo-bar see baz
With makeindex cross references could be specified with the
encapsulation mechanism. This has completely been removed in
In
@begin-comment One very interesting feature is the ability to check the validity of cross-references. @end-comment
tex2xindy recognises all index entries of the form
\index{...|\macro{where}}
as cross references. Here macro stands for an arbitrary macro
name and where is interpreted as the target keyword of the cross
references.
If you want to use these cross references with
(define-crossref-class "macro")
Additionally, you can assign specific markup to cross references using
the markup-crossref-commands.
Sometimes the keyword mappings don't work as expected. Especially in cases with several regular expressions one might get confused about what rule matches exactly when. We have incorporated a detailed logging mechanism that lets one step by step follow the rules that accomplish the keyword mapping.
When running -L'. This option followed by one of the numbers 1,
2, or 3 turns on the appropriate debugging level. Turning on level 2
or 3 and specifying a log-file with the command line option `-l'
a trace of the mappings is recorded in the log-file. A sample output
looks like the following:
Mappings: (add (merge-rule :eregexp `^\\bf{(.*)}' `\1' :again)).
Mappings: (add (merge-rule :eregexp `^\\"([AEOUaeou])' `\1')).
...
Mappings: (compare `\"A\"a' :eregexp `^\\bf{(.*)}')
Mappings: (compare `\"A\"a' :eregexp `^\\"([AEOUaeou])') match!
Mappings: (compare `\"a' :eregexp `^\\bf{(.*)}')
Mappings: (compare `\"a' :eregexp `^\\"([AEOUaeou])') match!
Mappings: (merge-mapping `\"A\"a') -> `Aa'.
This trace shows that initially two regular expression mappings have
been added to the rule set. The second section shows how the keyword
`\"A\"a' is compared to these rules and substitutions are
applied as matches are found. In the last line the result of the
keyword mapping is reported.
A very important feature is the ability to trace all markup tags
-t or insert the command
(markup-trace :on)
into the index style. This informs
<INDEX:OPEN>
<LETTER-GROUP-LIST:OPEN>
<LETTER-GROUP:OPEN ["a"]>
<INDEXENTRY-LIST:OPEN [0]>
<INDEXENTRY:OPEN [0]>
<KEYWORD-LIST:OPEN [0]>
<KEYWORD:OPEN [0]>
...
The symbolic tags directly lead one to the command that is responsible
for the definition of that markup tag. For example, the tag
LETTER-GROUP-LIST:OPEN indicates that the command
markup-letter-group-list is responsible for replacing this
symbolic tag by a real one.
Give it a try if you find yourself confused by your own markup
specification.