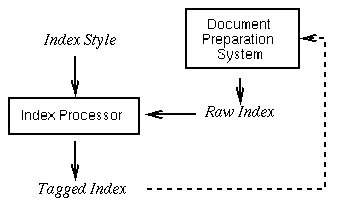
Usually document preparation systems produce some form data that describe the index entries and the locations they point to. This data is called the raw index since it consists of raw data which contains structured information about the entries of the index. The raw index is fed into the index processor and is processed according to a specification called the index style. This is a user-definable description how the index is to be processed, what sort rules for the keywords should be used, which kind of locations may appear, and finally, what tags should be emitted when writing the index into the output file. The result is sometimes fed back into the document preparation system, as it is in the case of TeX, or used otherwise. The following figure illustrates this embedding into the document preparation process.
The
In contrast, the output of the
In the following sections we introduce some terms that are necessary
to understand the way
The development of
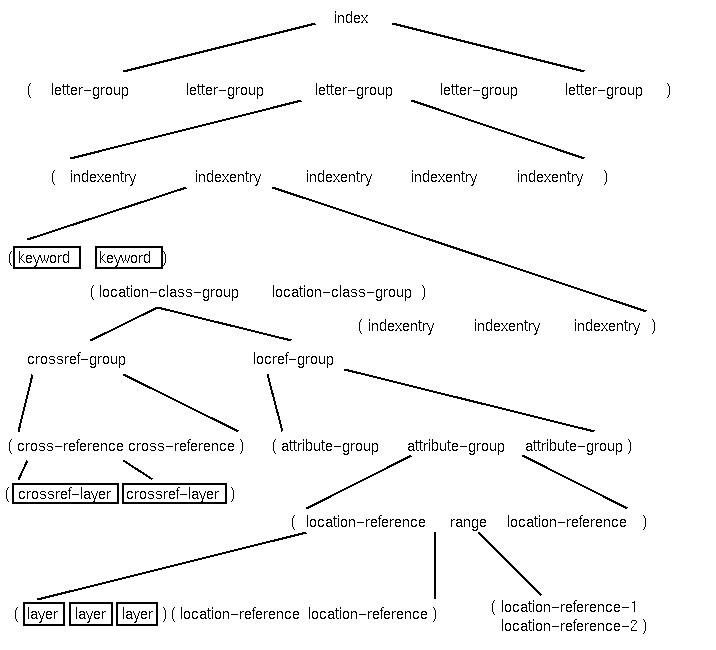
Boxed objects contain elements from the raw index such as the keywords or the location reference layers. We start from the root of the diagram and explain the different elements.
An index consists of a list of
The letter groups serve as containers for
B
bread 25, 27
butter 26
M
marmalade 19
milk 21
Here we have two letter groups for the letters `B' and `M' because the
keywords `bread' and `butter' share the same prefix `b' and
`marmalade' and `milk' share the prefix `m'. define-letter-group for further details.
An index entry consists of three components: the
bread 25-30
brown 26
white 27
This index entry consists of the keyword `bread', the location class list `25-30' and the sub-entries `brown 26' and `white 27'. The sub-entries themselves are complete index entries as well, forming a recursive data structure.
The keyword is the identifier of an index entry. It consists of a list of strings being the key if the index entry. In our model the keyword constists of a list of strings, since indexes are often organized hierarchically with different layers. In the example
bread 25-30 bread, brown 26 bread, white 27
we have keywords `bread', `bread, brown' and `bread, white'.
A keyword is actually separated into four different keys. The
The following figure describes this:
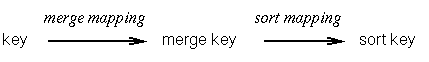
The merge-rule for further details about
defining the merge mapping.
The sort-rule for an
explanation how these mapping can be specified.
The
There exist two kinds of
location class groups namely
consists of a list of
Each
See command define-attribute-groups for further information about
the handling of attribute-groups.
An attribute group consists of a list of
Each
index entry of an index references at least one
"25" represents a page number.
"Chapter-3" represents the third chapter of a document.
"A-I" represents the first page, written in uppercase roman
numerals of the appendix `A', separated by a hyphen.
"2.3.4" represents the sub-sub-section 2.3.4 of a document.
As we can see, the location references are often composed
hierarchically of smaller entities, such as numbers or names. All
location references that belong to the same class form a
define-location-class for a
description how classes can be defined.
As we have seen in the previous section, location classes consist of alphabets and separators. xindy has the following built-in set of basic alphabets:
<tag/<tt/arabic-numbers// contains all non-negative numbers beginning
with zero: 0, 1, 2, ....
<tag/<tt/roman-numerals-uppercase// the roman numerals I, II, III,
(IIII/IV), V, ... It recognizes the old and new roman numeral system.
<tag/<tt/roman-numerals-lowercase// the same for the lowercase roman
numerals.
<tag/<tt/ALPHA// the US-ASCII alphabet (uppercase letters).
<tag/<tt/alpha// the US-ASCII alphabet (lowercase letters).
<tag/<tt/digits// the digits 0, 1, 2, 3, 4, 5, 6, 7, 8 and 9 in this
order.
The user is free to define new alphabets as he wishes. See the
commands define-alphabet and define-enumeration for further
details.
A complete location class can be defined by composing alphabets and
separators. The location class of the example "A-I" can be
defined as follows
(define-location-class "appendix"
(ALPHA "-" roman-numerals-uppercase))
This is a list that completely describes all possible instances of
this location class. Other valid members are A-II, B-VI,
etc. Location classes are defined with the command
define-location-class.
A define-location-class for further details.
Container for all
A
Each location reference contains a so-called
define-attributes must be used to define a set of attributes and
how they interact.